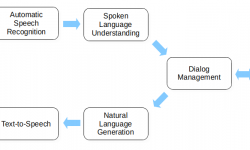
Podcast: COMPRISE, the privacy-friendly, inclusive voice interface
Listen to Emmanuel Vincent, the project coordinator of COMPRISE, Nathalie Vauquier, the engineer in charge of Inria’s software development in COMPRISE, and Brij Srivastava, a young researcher who has joined Inria Startup Studio on October 1, 2021, to create a startup exploiting the results of the project. https://www.inria.fr/en/podcast-comprise-privacy-friendly-inclusive-voice-interface