



Voice assistants like Alexa, Siri, and Google Assistant are still a relatively new technology for the consumer market. However, under the label of “Spoken Dialog Systems” (SDS), it’s a research area that has quite a long history. The classical architecture of an SDS typically looks something like this:
The user says something to the system, i.e., to his smartphone or to his smart speaker at home. Then, the system performs what is called “Automatic Speech Recognition”, turning the sound waves that arrive at the built-in microphone into a sequence of words. At the next step, and through the “Spoken/Natural Language Understanding” component, these words get parsed and interpreted so that the system gets some idea of their meaning, i.e., what the user actually wants. Then, via the “Dialog Management” component, the system can react appropriately: if the user asked a question, it can try to find the answer; if it was a command, it can try to execute it. For that, it interacts with some backend application; for instance, a knowledge base, an e-commerce system, or anything else that is in charge of the stuff that is not directly related to the conversational aspects of the interaction.
Sometimes, the system might need (or want) to reply to the user, for instance in the case when a question was asked. To do so, the contents of the reply first need to be determined by looking up for facts in a database, by searching the internet, or by any other way. Once the reply has been determined, it gets depicted in the form of a textual representation via the “Natural Language Generation” component. Then, the result must be turned into natural language so it can be communicated back to the user. Specifically, words have to be turned back into audio that sounds like a human voice, a task achieved via the “Text-to-Speech” component. All of these steps are illustrated in the following Figure.
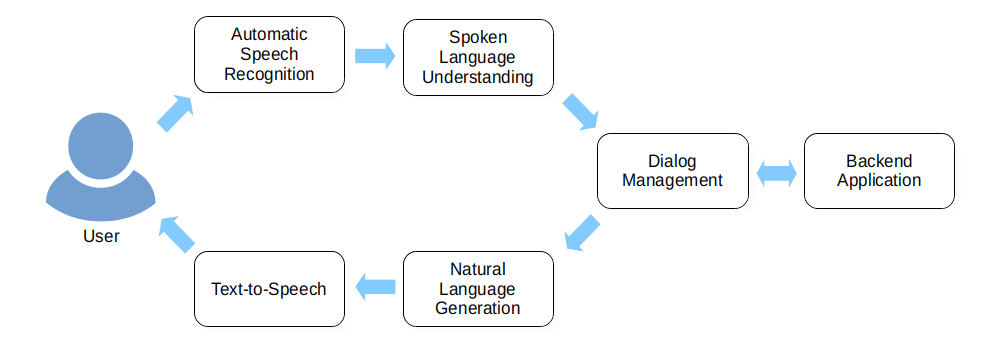
Based on the classical architecture description, it looks like the SDS functioning is very straightforward! But, is it really the case? Can it be considered as fully reliable? Let’s take a closer look.
There are a number of problems with this view of SDS, but for this article, let’s just focus on one of them, namely the problem that in general none of the steps represented by the upper boxes work absolutely reliably. If you have ever used automatic speech recognition before, you may have experienced that yourself: you speak into the microphone but the words that get written onto the screen are sometimes really not what you actually said!
Similarly, the interpretation of the recognized words by the “Spoken Language Understanding” component may fail, and so on. And it’s not hard to imagine that when more than one of these components get it wrong, all the individual mistakes add up and the performance of the SDS suffers dramatically. It’s basically as if the boxes in the Figure above were playing the children’s game of “telephone” (also known as “Chinese Whispers”).
In order to deal with this effect, modern spoken dialog systems use a trick that most children playing “telephone” would certainly consider cheating: each box does not just pass on to the next the best interpretation of their input but it considers multiple possibilities. For instance, the automatic speech recognition will not just output one sequence of words to the “Spoken Language Understanding” component, but rather a list of sequences. Say, the user really said: “Find me a nice cafe around here.” Then the “Automatic Speech Recognition” component might go: “I think I just heard the user say “find me an ice cafe around here” or “fine, me and ice cafe a round here” or “find me a nice cafe around here” or “find me a Nascar fee around here”. Good luck to the subsequent components!
One inherent problem with processing natural language is the large range of variation that you encounter. Take “Automatic Speech Recognition”, for example: everybody’s voice is different, men have (on average) a lower voice than women, people speak with different accents, and then there are words and expressions that are used only in certain regions but not in others (“Hey, y’all!”). Or, take “Spoken Language Understanding”: even the answer to a simple yes-no question can be expressed in so many different ways — yes, yeah, yup, uh-huh, hm, etc. For more complex utterances, it can get even more varied, yet the developer of a spoken dialog system is expected to program the system such that it can cope with most, if not all of these variations.
Well, before that developer can start programming, it would be a good idea to first collect some real-life data of people talking. The alternative — leaning back in your armchair and thinking really hard about how people talk — has proved to match reality so badly that it might be a feasible approach only for the most simple spoken dialog systems. Of course, no matter how much real-life data you collect, there is always a good chance of missing out on some important bits. In general, the more data of actual people talking you can get your hands on, the better your chances are of creating a robust system.
These data collections are not only useful for linguists to study how people converse. Manual data inspection is certainly handy for getting a feel about certain aspects of a dialog. But the task of writing some rules how a computer should process all the many variations of how people actually speak is still more than challenging. Wouldn’t it be better if the computer could somehow figure out by itself how to do that? Enter machine learning.
Supervised learning
On an abstract level, supervised learning can be illustrated with an analogy. Think of craftspeople who use a variety of different tools in their everyday work. Some of the tools allow various forms of settings for different kinds of jobs. And to get optimal results, the manufacturer might have designed the tool to come with one or more set screws that the experienced worker knows how to adjust.
Supervised learning can be seen as somewhat similar to that. The general task is this: find a way to map any valid input to some possible (and hopefully correct) output that we are interested in. For instance, for “Automatic Speech Recognition”, the input would be the sound waves produced by the user when saying a sentence and the correct output would be the sequence of the words the speaker said. In order to achieve this, the designer of a supervised learning approach will first devise a general “model” of computation: this includes how to represent the inputs and outputs in machine-processable form as well as an algorithm that applies certain computation on the input to achieve some output. The idea is that this algorithm also contains some “set screws”, and these greatly influence the result of the computation. Except they are typically called “parameters”, not set screws. Set the parameters wrong, and the computed output will be garbage. Set them correctly, and you have a “classifier” that can assign the correct output to any given input with a pretty high probability.
However, even an experienced designer could not set all the parameters optimally by hand because unlike with tools, there is not just a few set screws to fine-tune; we are talking potentially about millions of parameters here. Turns out that processing natural language is more complex than jointing lumber. In supervised learning, there is thus a “training phase” whose purpose is to find a good value for each of the model’s many parameters. And that’s where the collected data comes in handy again. What we need is a large amount of examples. Each example consists of a valid input together with the correct output. By looking at these examples, a machine learning algorithm can automatically tune the model parameters until the outputs produced by the “classifier” become as close as possible to the correct outputs. Typically, before the training starts, the parameter values are initialized at random and, as the training proceeds, they are constantly adjusted. When the training is done, the best values have been found — hopefully!
Remember how we said above that the model should work for “any valid input”? That is the important bit here because it means that a trained model can also classify new inputs that have never been provided during training. Of course, there is no guarantee that such unseen inputs will be classified correctly — this depends mostly on what computations the designer put into the model as well as the parameter tuning that came out of the training phase. But the cool thing is that in principle, this is an answer to the problem of variation in natural language: with supervised learning, there is some hope at least that a lot more user utterances can be processed correctly than would be possible with traditional, rule-based programming. And so, the state-of-the-art in many natural language processing tasks is based on supervised learning.
Read more:
- Automatic Speech Recognition: video or review paper
- Spoken dialog systems: video part 1 and part 2
Developer survey: Since you are here and interested in our project, could you please spare a moment to share your concerns and answer 12 questions related to developing voice-enabled apps.