



 Besides visual and tactile, the Next Generation Internet will rely more and more on voice interaction. This technology requires huge amounts of speech and language data in every language to reach state-of-the-art performance. The standard today is to store the voices of end users in the cloud and label them manually. This approach raises critical privacy concerns, it limits the number of deployed languages, and it has led to market and data concentration in the hands of big non-European companies.
Besides visual and tactile, the Next Generation Internet will rely more and more on voice interaction. This technology requires huge amounts of speech and language data in every language to reach state-of-the-art performance. The standard today is to store the voices of end users in the cloud and label them manually. This approach raises critical privacy concerns, it limits the number of deployed languages, and it has led to market and data concentration in the hands of big non-European companies.
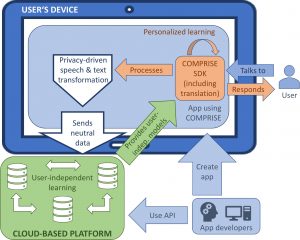
COMPRISE defines a fully private-by-design methodology and tools that will reduce the cost and increase the inclusiveness of voice interaction technology through research advances on privacy-driven data transformations, personalised learning, automatic labelling, and integrated translation. This leads to a holistic easy-to-use software development kit interoperating with a cloud-based resource platform. The sustainability of this new ecosystem will be demonstrated for three sectors with high commercial impact: smart consumer apps, e-commerce, and e-health.
COMPRISE will allow virtually unlimited collection of real-life non-private quality speech and language data; enable businesses in the Digital Single Market to quickly develop multilingual voice-enabled services in many languages; allow all citizens to transparently access contents and services available in other languages by voice interaction in their own language; result in cost savings for both technology providers and users. It will find application in many sectors beyond those demonstrated, e.g., e-government, e-justice, e-learning, tourism, culture, media, etc.
 |
COMPRISE has received funding from the European Union’s Horizon 2020 Research and Innovation Programme under Grant Agreement No. 825081. |