



Removing sensitive portions from a text, sometimes known as “sanitizing”, is often done by simply blackening the relevant words. Many people have seen such a redacted document at some point, it’s a technique commonly applied to classified government reports, for instance. A prominent example of such a document from recent times is the so-called Mueller report, which was only released to the public in redacted form.

Figure source: Mueller report
When this technique is implemented properly (i.e., the blackening cannot somehow be undone), it arguably provides a high level of privacy protection. However, it also has some downsides. For one, it makes it absolutely clear to everyone that the document, in fact, has been transformed, and also exactly which parts were edited. In some situations, this might not be desirable. Further, blackening some portions of a text is akin to deleting them and thus quite drastic. Let’s apply redaction to our tried and trusted dialogue example which was discussed in our previous blog post as an illustration:
- USER: New calendar entry: meeting with ▬▬▬▬▬ from ▬▬▬ ▬▬ ▬▬▬ .
- SYSTEM: What time?
- USER: ▬ ▬▬▬ ▬▬ . And please look up train connections to ▬▬▬ for ▬▬ ▬▬ .
The problem is that what remains is quite difficult to read: without the redacted words, the sentences become ungrammatical. But the whole reason we are interested in privacy-transforming such dialogues in the first place is that we want to use more data to train machine learning models on them. Ungrammatical, ambiguous and often non-sensical data such as the above are very limited in their usefulness towards that goal.
An alternative to blackening or removing sensitive words is to replace them with proxy words that keep the sentence structure intact but still improve privacy. It seems intuitive to use some kind of randomness in such a replacement approach, as opposed to some pre-defined mapping that would be trivial to reverse. At the same time, fixing a mapping for a specific context, say, the course of one document, makes sense too: always replacing each occurrence of a certain term with the same (random) replacement term guarantees coherence across the transformed document.
There is, however, a counter-argument to be made here. As well as modern Named Entity recognition systems perform, there is a chance that they occasionally miss one. Now, if an attacker got a hold of a transformed text where all occurrences of some private entity had been replaced by something else except for one, there is a good chance that from context, it would become apparent that that one un-replaced instance was the true word for all the other instances that did get replaced. Not good. If instead all of the same original words got replaced by different words every time, missing one would not stand out at all. But, again, it would come at the cost of losing text coherence.
The main question, however, is how to select the replacement terms for the identified private entities?
Replacement strategies
Let’s quickly discuss two aspects here: how to choose random replacement words and what to do about multi-word expressions.
In order to select replacement words by means of a random sampling procedure, we require two things: a vocabulary of candidate words and a probability distribution that tells us for each word in the vocabulary how likely it is to get selected as a replacement. So, where should those two things come from? A number of possibilities are conceivable.
For the vocabulary, here are two ideas: if you already have collected a sufficient amount of data before you want to transform them, you can first identify the contained Named Entities and extract the vocabulary from them. Naturally, it makes sense to have a separate vocabulary for each type of Named Entity, i.e., one for person names, one for organizations, etc. The advantage of extracting a vocabulary directly from collected data is that it will be an in-domain vocabulary which lowers the chance that some completely unrealistic replacements are chosen. If that is not an option, a general list of names, organizations, dates, times extracted, e.g., from census data, company registers, Wikipedia, etc., could be used instead.
Depending on how exactly the vocabulary was chosen, different options for suitable probability distributions become available. Of course, a uniform distribution where each candidate replacement is selected with the same probability is always a possibility. When the underlying vocabulary has been extracted collected data, it is possible to use a distribution based on the frequency of occurrence in the data, which in some situations might be desirable. But since the purpose of collecting data is to use them for a subsequent learning task, we could also try to design an artificial distribution that is optimal for whatever task the data is used for.
In all of this, one details gains prominence, and that is the fact that a lot of times, named entities consist of more than one word, as we have already seen in our small dialogue example (“Mrs. Norton” or “next Tuesday”). Intuitively, it makes sense to replace the full expression with another full expression — so, for instance, replace “Mrs. Norton” with “Mr. Smith”. However, text coherence is again what poses a challenge here: the same entities can be referred to by different expressions. For instance, the same text could use “Mrs. Merkel”, “Angela Merkel”, “Chancellor Merkel”, etc., all to refer to the head of the government of Germany. When each of these expressions gets randomly transformed into a completely unrelated replacement, it will be quite difficult to understand the meaning of the text after it has undergone transformation.
This is a difficult problem. A simple, albeit more than imperfect approach to solving it could be to not replace multi-word expressions as a single unit but instead replace each contained word individually. Especially if we had a means to maintain more fine-grained replacement vocabularies, e.g., one for first names, one for last names, one for titles, etc., then we would have a chance to end up with a coherently transformed text. An example for such a single-word transformation could e.g., look like this:
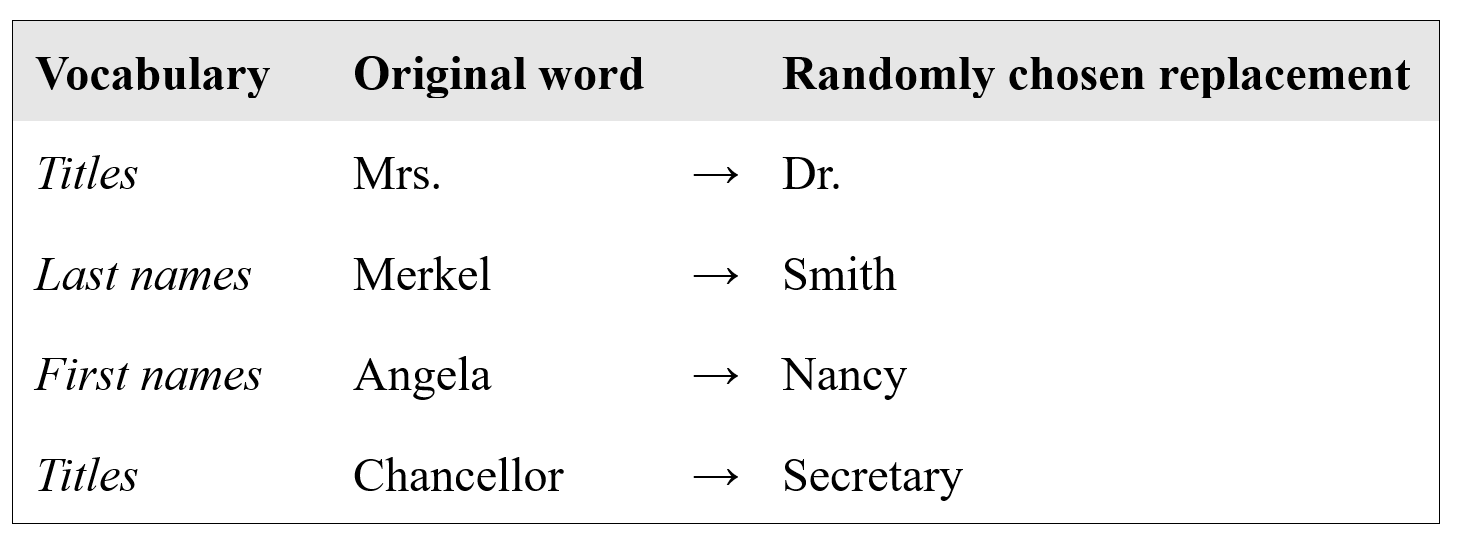
But such an approach only really works under the best of circumstances, such as in this idealized example. In general, the coherence problem is very hard to tackle. For instance, the question of what is a first name and what is a last name is very hard to pin down, and in some cultures these notions might not even be applicable at all.
Our simple Named Entity system from above does not distinguish between the different parts of a multi-word person name. Nevertheless, it is a replacement strategy that has enough merit to be considered as an alternative to always replacing full entities as a whole. Our next blog post will tell you more about this! Stay tuned!
Developer survey: Since you are here and interested in our project, could you please spare a moment to share your concerns and answer 12 questions related to developing voice-enabled apps.