



Healthcare has been one of the countless beneficiaries of the revolutionary advances that widespread computing has brought. Fast, efficient data organisation, storage and access that have greatly sped up the medical enterprise, yet many low hanging fruits remain hanging. Chief among those is the increased application of technologies that can process speech.
In this post, we’ll share with you how speech technology can improve healthcare in the three following ways. (1) Speech technology can be used to improve the efficiency of medical personnel. (2) Voice-based interactions for patients and hospital visitors can simplify access to information and speed up the registration process. Finally, (3) voice signal analysis can be used for earlier diagnosis and to help track the changes of medical condition over time.
Let’s explore these three ways in detail.
Helping physicians
Research has shown that medical personnel unsurprisingly spend a significant amount of their time interacting with their patients using their voice, but, surprisingly, they can spend even more time documenting these physician-patient sessions (Arndt et al., 2017). Taking notes, creating and updating medical records and so on, take up a considerable amount of time. Physicians often make use of any resources available to them to speed up this process. For example, a physician can record the session with a patient to be able to revisit details of it later or employ a human scribe, that can either transcribe the session records or document the session directly as it unfolds. It is no secret, however, that the requirement of additional personnel with non-trivial training makes these options somewhat luxurious and unreliable.
The first and most obvious remedy for this time sink is to use a digital dictation device including a speech-to-text system (introduced in our previous post) that automatically processes the recordings and prepares a draft transcription of the session, which the physician or a trained scribe can quickly post-edit. Speech-to-text can also be used to transcribe the dictated post-session recordings made by physicians. Processing medical speech is not without its challenges, though. While there are multiple products on the market that serve this use case already, it is useful to look at the challenges these systems are facing.
Like many other non-professional recordings, the audio quality in healthcare is very inconsistent. There’s often a background noise of varying amounts, and the speakers are also frequently unclear, specifically when speaking too fast or too far from the microphone. Good audio quality is usually not the primary concern of neither the patient nor the physician during a session. Thus, any speech recognition system that has been trained on clean audio will probably have a bad time trying to make sense of the vast possible range of acoustic conditions in medical recordings. Fortunately, special speech-to-text training techniques and data preparation can help create noise-robust systems that can provide much better recognition quality with such inconsistent inputs.
Also, medical language is highly specialised, with vast vocabulary, acronyms and other forms of expression not found in common language. Commercial speech-to-text systems are often trained to cover as many application domains as possible. Therefore, they are called general domain systems. Using a general domain system on a narrow domain like the medical one often results in a noticeable drop in recognition accuracy. Fortunately, we can use domain adaptation to adjust our general domain speech-to-text system to a narrower domain or, given enough data, even train a domain-specific system. These systems trade off accuracy on the general domain for much better accuracy on the domain of interest. Given the vast size of medical vocabulary, it can sometimes make sense to focus on a particular medical specialisation such as, e.g., radiology or dermatology.
While speech-to-text is a significant boost on its own, we can make further improvements by building on top of it. We can use speech-to-text as a stepping stone to build smarter downstream applications that can deal with the recognised text in a useful manner. For example, it would be useful to extract structured information from the raw transcript, and try to prepare draft medical records, which often follow a regular structure. Spoken language understanding tools (also introduced in our previous post) can be used to extract information from raw transcripts, starting from recognising highly regular patterns in text such as medicine dosage and standardised measurements, to classifying and extracting more nebulous entities such as medical history, symptom descriptions, chief complaint by the patient, etc. The extracted structural information can then be used to prepare the actual record drafts, a template where the physician must fill in the missing pieces and check the rest.

Figure 1 – Sample medical record preparation process using speech-to-text and natural language understanding tools
Assistance for patients and visitors
It’s not only doctors and other medical personnel that speech technologies can help. A clever combination of speech recognition, speech synthesis and chatbot technologies can result in a more useful virtual assistant in hospitals, which is capable of helping people with common questions and problems. Eventually, this can optimise the workload of hospital personnel and reduce the time people have to wait in queues for information and registration. Such a hospital assistant can, for example, help with directions or guide through the proper hospital processes for getting to where the visitor or patient has or wants to be.
Beyond procedural help in the hallways and corridors of a hospital, speech technologies can also have a positive impact on the quality of life of patients with disabilities. Speech recognition and speech synthesis together can provide a practical substitute for the mostly visual interface of a modern computer, enabling access to many of the benefits of modern computing (Hawley, 2002). Among the benefits, we can mention the example of a person with vision impairments who can enjoy voice feedback from a computer relaying the information that would be traditionally presented on the screen. Another example can be a person with limited mobility who can interact with and issue speech commands to modern virtual assistants, which can automatically perform a range of useful tasks, thanks to modern connectivity enabled household objects.
Most of these helpful use cases require integration between speech technology, which can provide voice interfaces, and the actual systems doing something useful, that can’t yet be accessed by either the visitor or the patient. While there are some existing integrations out there today, the number of research and commercial interests in this space should ensure that we’ll see such applications increasingly often in the future.
Diagnosis and analysis
The frontier of speech technology in health goes beyond assistance. A highly active and perspective area of speech technology research is diagnosing various physical and mental disorders that affect patient’s speech and other vocal expressions. A diverse set of technologies is used for diagnostic purposes, and a significant part of them do not only consider the linguistic contents of speech, i.e., what is being said, but pay more attention to its paralinguistic features, i.e., how it’s being said. Both the contents and the manner of speech can provide important clues to determine more accurate diagnosis.
Quite obviously, speech technologies can be used to diagnose, classify and track speech disorders. These technologies can be used to identify acute speech disorders establishing initial diagnosis without the need for expensive and potentially painful medical procedures. Likewise, keeping track of how pronunciation changes over time can help keep a non-perceptual record of how a disorder is progressing or receding. Providing or improving a diagnosis by using just an audio recording does not require expensive medical equipment. Adding to this, it helps avoid subjective perceptual judgments by the clinician and, most importantly for the patient, it is painless and easy (Wu et al., 2018).
Similar methods can be applied to track and provide early detection of problems during child development, where early diagnosis of a speech disorder can help provide effective early intervention to reduce potential problems later. One simple implementation would be a convenient mobile application that a parent can use to record their child speaking a set of carefully chosen benchmark words, which can then be analysed and compared to a set of ground-truth recordings from known healthy recordings (Kothalkar et al., 2018).
Speech signal analysis could also prove itself useful for early diagnosis of neurodegenerative conditions, some of which are tricky to diagnose early as the symptoms are subtle and could be explained by several other conditions. Prominent examples, where speech signal analysis has shown promise in early detection are amyotrophic lateral sclerosis (An et al., 2018), Parkinson’s disease (Tsanas et al., 2012) and brain injury (Falcone et al., 2013). Many of the markers used today rely on self-assessment or performance of tasks that are judged perceptually by a human observer, but these conditions affecting the brain usually become noticeable to a human only after significant brain damage has already occurred. Statistical analysis of speech recordings, however, has shown to be more sensitive than human ear to early symptoms (An et al., 2018).
It has been shown that even subtle mental disorders can be analysed using both the contents of patient’s speech and the manner of speech (Cummins et al., 2015). For example, research shows that depression notably affects the patient’s vocabulary, and this change can be statistically measured to bolster the clinician’s confidence. On the other hand, subtle pronunciation differences can also betray the speaker’s mood and state of mind to not just a perceptive human listener, but also to statistical machine analysis.
While many of these methods promise early, easy and, most importantly, objective diagnosis for a whole range of medical conditions, currently they are also limited to mostly research laboratories and curated medical datasets. In other words, it’s still mostly the future, but early signs give us cautious hope that these technologies might soon deliver substantial real benefits for doctors and patients.
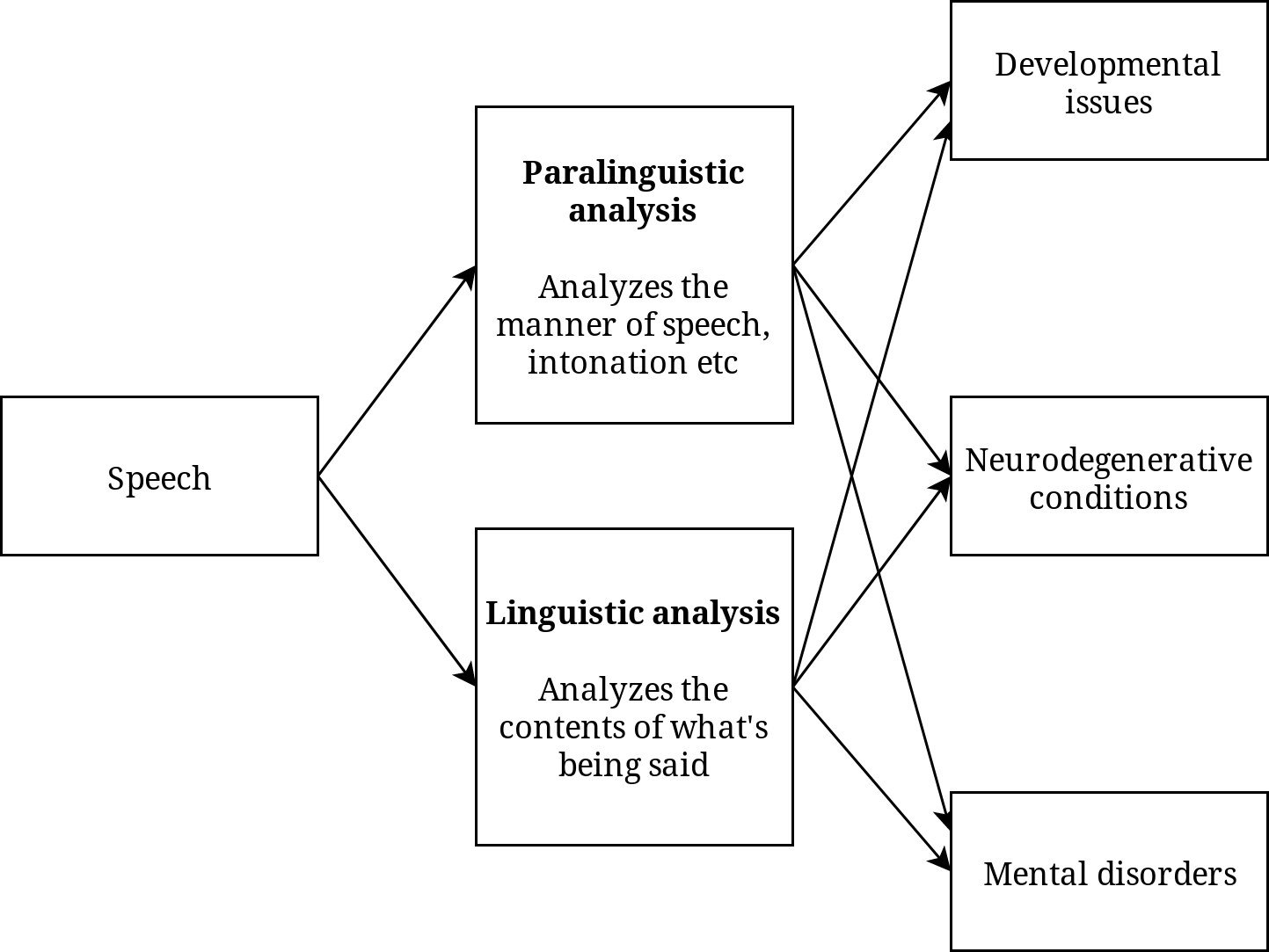
Figure 2 – Research into automatic paralinguistic and linguistic analysis of patient’s speech promises improvements for diagnosis of a range of medical conditions.
In this blog post, we have described just a few promising avenues, where speech technology can help both the medical practitioner and the patient. While many of the above mentioned technologies have been tested only in research and experimental settings and thus can be considered somewhat pre-mature, the growing number of these technologies also points towards the potential for improvement on multiple levels in healthcare by employing these technological advances.
It should be noted that medical industry is one with high stakes and moral responsibility. Medical data is often highly sensitive, and particular care should be taken to protect the privacy of the patient. The technologists and researchers bringing these improvements to life should also pay attention to not overselling and carefully indicating where the new technology still falls short. The improvements here should help and facilitate the job of a medical expert, but can’t substitute for it.
Read more:
Written by:
Attribution:
This blog post uses icons from FontAwesome under Creative Commons Attribution 4.0 license. Please find their license here.
Developer survey: Since you are here and interested in our project, could you please spare a moment to share your concerns and answer 12 questions related to developing voice-enabled apps.