



Protecting User Privacy with Voice Conversion
With the increasing popularity of smart devices, more and more users have access to voice-based interfaces. Voice-based interfaces offer simple access to modern technologies and enable the development of new services. The building blocks behind these speech-based technologies are no longer handcrafted but learned from large sets of data. [Ref1]
This is the case, for instance, of Automatic Speech Recognition (ASR), where vast quantities of speech, in all languages, are needed and continuously collected to improve performance and adapt to new domains. This collection and exploitation of speech data raises privacy threats since speech contains private or sensitive information about the speaker (e.g., gender, emotion, speech content, etc) [Ref2]. Furthermore, a speaker’s voice is a biometric characteristic that can be used to identify the speaker with i-vector [Ref3] or x-vector [Ref4] based speaker recognition (a.k.a., authentication) [Ref5]. To address this privacy issue, various anonymization techniques have been studied with the goal to transform speech signals in a way that preserves the content of the speech signal, but removes the features that are related with the speaker’s identity. These techniques include noise addition [Ref6], speech transformation [Ref7], voice conversion [Ref8], speech synthesis [Ref9], adversarial learning [Ref10], etc. However, as a privacy preservation mechanism, the transformation method must achieve a suitable “privacy & utility” trade-off. The “utility” mentioned here is normally assessed by the accuracy of downstream processing steps (e.g., how does the Word Error Rate (WER) of the ASR system differ when compared to non-modified speech) and “privacy” is measured through speaker recognition evaluations (i.e., is it possible to re-identify the speaker).
Voice Conversion
The idea behind anonymising a voice by “voice conversion” is to apply the voice characteristics of a different speaker to the original speech signal while keeping the spoken content understandable. This way, if an attacker gets hold of the speech signal, it will be difficult for the attacker to re-identify the original speaker. The main advantage of voice conversion is that it does not try to get rid of the speaker’s voice characteristics, but rather enforces a different speaker’s characteristics over it. In other words, to maintain the balance of “privacy & utility”, it is easier to replicate another person’s voice than it is to neutralize the original voice: “I want this voice” than “I do not want any voice”.
How do we evaluate voice conversion?
In order to evaluate the quality of the anonymization (i.e., how well the privacy of the speaker is protected), we evaluate how easy it is for an attacker to re-identify the original speaker. To re-identify the speaker of a transformed utterance, the attacker compares it with one so-called enrolment utterance from every possible speaker. This is done by computing the distance between the utterances using a trained distance model, which is a method similar to that used in the Voice Privacy Challenge [Ref11].
To evaluate this, we use Top-k Precision, a metric which measures how often the true speaker is among the k speakers which are found to be most plausible by the attacker. In addition, we can use different types of attackers that are defined based on their knowledge of the anonymization method and the effort put into conducting the attack.
- Ignorant: the attacker does not know about the anonymization method and uses un-transformed enrolment data.
- Lazy-informed: the attacker anonymizes their enrolment data with the same anonymization method.
- Semi-Informed: in addition to anonymizing the enrolment data, the attacker re-trains the distance model with anonymized data.
X-Vector Based Voice Conversion
Using the setup proposed in [Ref12] and illustrated in the Figure 1, we extract from a given speech signal, 1.) the content portion in the form of pitch and bottleneck (BN) features and 2.) the speaker portion in the form of an x-vector. The pitch encapsulates how the speech signal was spoken and the BN features encapsulate the verbal contents of the speech signal. The x-vector embeds in a single vector the speaker’s characteristic (e.g., x-vectors are used in speaker verification systems to distinguish utterances from different speakers).
The goal of this method is to re-synthesize a speech signal that maintains the same verbal contents while enforcing a new target x-vector corresponding to another speaker. To do this, two modules are used to generate the speech signal: 1.) a speech synthesis acoustic model that generates Mel-filter bank [Ref13] features giving the pitch, the target x-vector, and the BN features, and 2.) a neural source-filter (NSF) waveform model that produces a speech waveform giving the pitch, the target x-vector, and the generated Mel-filter banks.
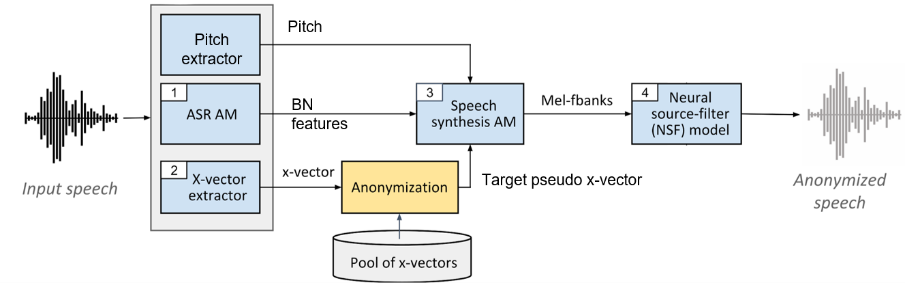
Figure 1 : X-vector based voice conversion technique.
With the x-vector retrieved from the original speech signal, a target, replacement x-vector needs to be selected from a pool of speakers. Multiple selection strategies were experimented with some taking into consideration the original x-vector (e.g., selecting from the farthest or nearest x-vectors to the original speaker), but the most successful selection techniques were independent of the original speaker. Mainly: 1.) the Random strategy where we average N x-vectors uniformly selected at random from the same gender as the original speaker and 2.) the Dense strategy where we identify clusters of x-vectors in the pool and rank them based on their density (i.e., number of members), then we randomly select a cluster out of the densest clusters and then average half of its elements selected at random.
Privacy evaluation
As expected, the identification of the speaker’s voice becomes more difficult as the number of possible speakers increases. This is the same for both original and anonymised data, however, the identification of the original, non-anonymised voices remains well better than chance, even among thousands of possible speakers. As for the transformed, anonymized data, the identification performance soon reaches the level of chance, or worse as the number of speakers increase. With the re-identification proving to be more difficult for the transformed voices, we look at the probability that the target voice is in the top 20 possibilities (Top-20 Precision). As indicated in Figure 2, the possibility that the anonymised data is in the top 20 drops drastically compared to the original voice data (Baseline). This indicates that after anonymising the voice, it becomes much more difficult for an attacker to re-identify a speaker. Furthermore, Figure 2 indicates that even when the attacker is highly motivated and informed about the anonymisation method, hiding an anonymised voice with 52 other speakers is equivalent to hiding the original non-anonymised voice with 20,500 other speakers.
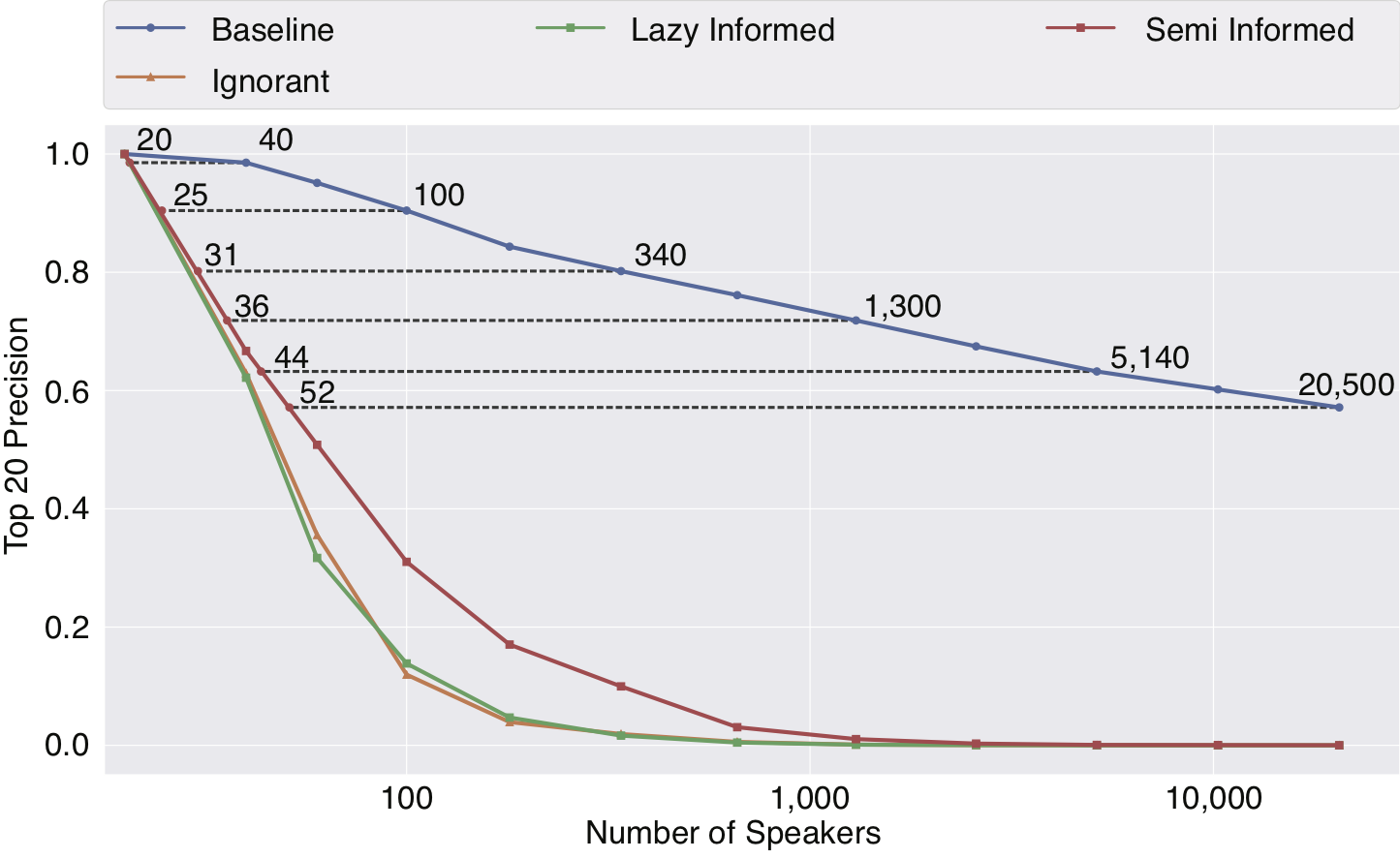
Figure 2 : Top-20 precision of speaker identification for different attackers as a function of the number of possible speakers. The numbers of speakers needed before anonymisation (N on blue curve) and after anonymisation (n on red curve) to achieve an equivalent drop in precision are highlighted.
What about utility?
To evaluate whether the speech signal that was anonymised using the method mentioned above has preserved the spoken content and the overall diversity of the speech, we verify if the anonymised speech is usable for training an ASR system. For this evaluation, 4 cases were studied depending on whether the data to decode and the data to train are original or anonymized. As can be seen from the WER (lower is better) in Figure 3, anonymized data can be used to train an ASR model capable of decoding anonymized data with an error rate comparable to the baseline.
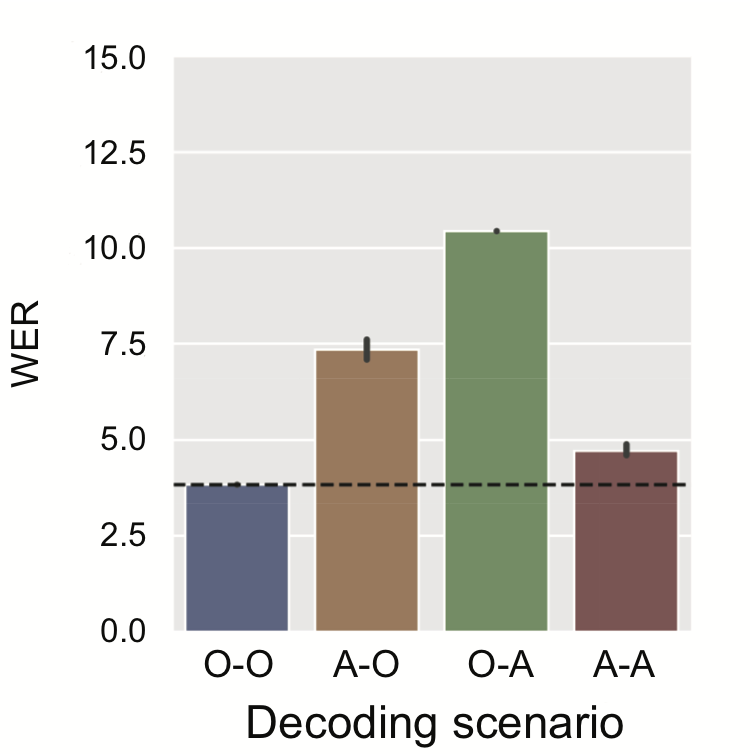
Figure 3 : Utility evaluation with ASR (O = Original, A=Anonymized, X-Y means = Decoding X using a model trained on Y).
Conclusion
Speech anonymization based on x-vector voice conversion lowers the re-identifiability of the speech signal significantly even when the attacker has knowledge of the voice conversion method that was used. Furthermore, results from the ASR model training show little difference with models trained on the original speech, indicating that the anonymized data preserves the spoken content. This can be seen as a win-win situation between privacy and usability.
References
[Ref1] COMPRISE Blog Post: “Spoken Dialog Systems – are they fully reliable?”, 2019.
[Ref2] Computer Speech and Language Journal Paper: “Preserving privacy in speaker and speech characterisation”, 2019.
[Ref3] IEEE Transactions on Audio, Speech, and Language Processing Journal Paper: “Front-end factor analysis for speaker verification”, 2010.
[Ref4] ICASSP Conference Paper: “X-vectors: Robust DNN embeddings for speaker recognition”, 2018.
[Ref5] COMPRISE Blog Post: “10 Privacy Risks Associated With Voice-Enabled Technologies”, 2019.
[Ref6] ICASSP Conference Paper: “Privacy-preserving sound to degrade automatic speaker verification performance”, 2016.
[Ref7] Paper on Cryptography and Security: “Voicemask: Anonymize and sanitize voice input on mobile devices”, arXiv preprint arXiv:1711.11460, 2017.
[Ref8] Odyssey Conference Paper: “Convolutional neural network based speaker de-identification”, 2018.
[Ref9] ISCA Speech Synthesis Workshop Paper: “Speaker anonymization using x-vector and neural waveform models”, 2019.
[Ref10] COMPRISE Blog Post: “Privacy-driven speech transformation with adversarial learning”, 2019.
[Ref11] VoicePrivacy Challenge: “The VoicePrivacy 2020 Challenge Evaluation Plan”, 2020.
[Ref12] Interspeech Conference Paper: “Design choices for x-vector based speaker anonymization”, 2020.
[Ref13] Fayek Haythem “Speech Processing for Machine Learning: Filter banks, Mel-Frequency Cepstral Coefficients (MFCCs) and What’s In-Between”, 2016.
Written by:
Dr. Mohamed Maouche
Postdoc at INRIA Lille Nord Europe – Magnet Team
Developer survey: Since you are here and interested in our project, could you please spare a moment to share your concerns and answer 12 questions related to developing voice-enabled apps.