



In our previous posts [Post1] and [Post2], we have presented a rather streamlined version of the issue at hand and introduced quite a few simplifications along the way. Still, we have seen that privacy transformations of text are complex. A number of challenges presented themselves and we have discussed a few alternative approaches for each of them. So, then the question arises which of the alternatives should one choose in practice? Which one is the best?
In order to answer that, we should have a means to measure the two competing dimensions we have considered so far: the protection of users’ privacy on the one hand and the usability of the transformed data for subsequent processing on the other hand, i.e., some machine learning task.
One of the most commonly used frameworks to express the loss or gain of privacy is called Differential Privacy. It is a mathematical formulation that uses two values to express privacy, ε and δ. In a simple version δ is set to 0, and ε is a nonnegative value that expresses how much of a person’s privacy is lost even after it has been transformed with one of the variants outlined above. Thus, the lower ε is, the better.
Since the first step in our procedure is the automatic identification of privacy threatening entities in dialogue transcripts, it is clear that the quality of the automatic identification method is the key factor here. If it were perfect, that is if all sensitive information could be identified with 100% accuracy, we could expect zero privacy loss if we used a random replacement strategy. In practice, even people aren’t always 100% correct and thus even the best algorithms might miss some instances. The privacy loss then depends on how well the algorithm actually works. Let’s say that on average, it can identify the sensitive entities correctly in 80% of the cases. Or maybe 90%. Or — let’s just be general, since the exact percentage varies from case to case — let’s say consider some percentage p and say that the algorithm can identify the sensitive entities in p percent of the cases.
Then we have found out that the privacy loss ε can be calculated according to the following formula: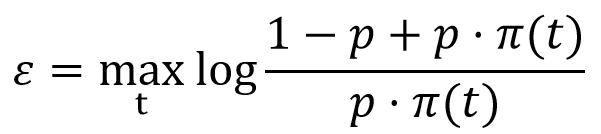
Here, π(t) refers to the probability distribution from which we sample whenever we need to replace a word, and the sampled words are drawn from a finite set of words indexed by t. However, there is a caveat. This formula only holds if we introduce the assumption that the replacement word is chosen independently from the word that is replaced. That is bad news for text coherence (sigh, again!) since it implies that different words could in theory get replaced by the same replacement. Ideally, we would like to avoid that situation.
But focusing more on the privacy guarantee that text transformation can give users, we can see that a perfect Named Entity recognizer would lead to perfect privacy, independent of the used replacement strategy. As we’ve discussed above, such a performance is difficult to achieve in reality. Thus, when we’re dealing with imperfect identification of sensitive words, the choice of probability distribution becomes relevant. The lowest privacy loss is achieved if π selects from the replacement candidates with equal probability. And intuitively, that makes sense: remember, we’re talking about the case where the Named Entity recognizer sometimes misses relevant information. So the best we can do is somehow “hide” those cases: when an attacker finds a Named Entity in the transformed text, it would be ideal if it were very difficult for him to tell whether he’s looking at something that is the result of a replacement, or if it’s something that was in the text originally and was missed by the Named Entity recognizer. A π that gives equal probability to all replacement candidates makes that task the hardest, while a strategy like redaction makes it the easiest: whenever a symbol in the transformed text is not redacted, the attacker can be sure that it must have been there already before the transformation.
For measuring usability on the other hand, it really depends on what the concrete task is that you have in mind, i.e., what you want to do with the data. For instance, we ran some experiments training our own Named Entity Recognizer on transformed data to see how the different transformation strategies would impact the performance. The results were quite interesting.
We trained and tested our recognizer on different portions of a data collection of English phone conversations in which two people negotiate the arrangements of a planned business meeting (Verbmobil corpus). The training portion of the data was transformed with three different strategies: redact (using the same symbol, the word “PLACEHOLDER”, for each replacement to simulate blackening out the words in question), a word-by-word replacement strategy (but always replacing with words of the same type), and a strategy where entities as a whole were replaced. In each of the three variants, we first trained the recognizer and then tested its performance on the test portion of the data.
The following table shows the result. To quantify the performance, we used the common F1-score where 0% is the worst possible and 100% the best possible performance.
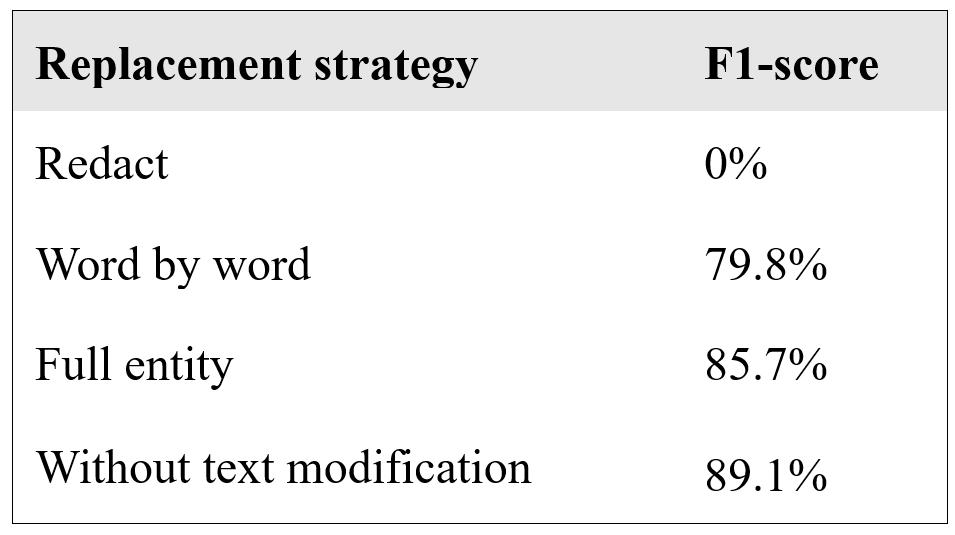
As we can see, while redaction is not only the worst in terms of preserving privacy, it also leads to the worst performance when the redacted data is subsequently used to train a certain machine learning model. The other two models are pretty good, with the full entity replacement approach slightly in the lead. Apparently, the gained grammaticality trumps potential gains in text coherence. Since our training method only considered isolated sentences and not longer parts of a dialogue, this is not surprising. A full description of this work can be found in our deliverable D2.1 – Baseline speech and text transformation and model learning library.
Believe it or not, we’ve only scratched the surface of trying to find ways to better protect the privacy of voice assistant users. But the issue is real. If you’re using voice assistants today, chances are your voice is getting recorded, transcribed and stored in the cloud. Work like ours done as part of the EU-funded COMPRISE project is an important step toward providing more security and privacy for all users of voice-based systems.
But we’ve only done a first step, and we had to do a number of simplifying assumptions in order to get there. For instance, we’ve only looked at five specific types of named entities because in one specific context, business meeting, these are good candidates for information that should get sanitized. However, we’ve already seen that a more fine-grained approach (first names, last names instead of just names) would give us more options for concealing sensitive information more coherently. At the same time, a conversation on business meetings might touch on other sensitive information that’s neither the name of a person or an organization, a location, or a date or time. And in other domains, i.e., when the topic of conversation is a different one, that aspect gets multiplied. Consider for instance online shopping with voice assistants: the things one buys lend themselves very well to profiling the buyer, they might even allow to uniquely identify them. Some items in an online shopper’s cart surely have the potential to severely impact that person’s life if they became publicly known — for instance, when the shopper is an underaged girl ordering a pregnancy test, or someone buying drugs specific to a terminal illness. But we don’t have to be morbid to illustrate the risks: simply telling one’s credit card number to the voice assistant is probably something that few people would like to become part of a data collection somewhere in the cloud — yet none of these examples are covered by the Named Entity types we used in this blog post.
The replacement strategies discussed here also require further research. We’ve made clear the trade-off between protecting the user’s privacy and the usefulness of the transformed data. Grammaticality and coherence are two aspects highlighted above but the solutions presented cannot provide a complete remedy for the problem. For instance, when replacing a person’s name with a random other name, it is a good idea from the privacy point of view to allow male names to be replaced by female names and vice versa since this way the gender of the original person gets obfuscated. But in order to keep the rest of the conversation coherent, a perfect text transformation might also have to consider adjusting personal pronouns referring to the transformed names accordingly. This is absolutely not trivial.
This is not a complete list of open challenges — not at all. There’s still a long way to go. In the COMPRISE project, however, we strongly believe that people’s privacy is such an important value that it is worth going down that route.
The first step has been taken. But there are many more to come.
Be sure to check out our blog regularly in the future for more updates!